Web scraping with Cheerio, Axios, and Express

Web Scraping is the process of extracting data from the DOM of a website and then returning it data for external use in another application.
Web Scraping is a very complicated yet simple technique and can be useful in different cases and can reduce the amount of effort needed by a developer to create a valid JSON or API for their application.
For example, you might want to build an app that displays product items and their current price list directly on the app, and sourcing for this data or creating it manually might not be the ideal thing to do due to the time it will take to create the data. Then in this case you might need to look for an online store with the exact data and price list you are looking for and then scrap the data directly on your app.
Another scenario where web scraping can also be very useful might be an app that requires users to be able to search items or places based on a certain location. With web scraping, you can scrap popular map platforms like Google Maps to track changes in different locations and return the result to the users.
In this blog post, we are going to be looking into how to implement web scraping using Node.js. With Node.js we can install essential packages that can be used to scrap data on the web such as Cheerio, Express, Axios and Nodemon.
By the end of this blog post, you should have a basic understanding of how web scraping works with Node.js
Prerequisites
It would help if you had a basic understanding of the following;
JavaScript DOM Manipulation
Selecting element from the DOM using JavaScript
CSS Selectors
Axios
How to install packages in Node.js
Now let’s begin,
Overview
In this blog post, we will be scraping a blog post with 50 book reviews. We will be scraping the following data;
id: random numbers from the blog as our id
title: title of the book
author: the name of the book author
about: a short description of the book
imgUrl: the URL where the cover of the book is saved.
After that, the data will be converted to a valid JSON file and exported.
check the finished preview here 👉 books.json and the full project here 👉 on GitHub.
Dependencies
The following is a list of dependencies we will be working with in this project.
Cheerio: Cheerio is an npm package that provides APIs that make it easy to traverse/manipulate DOM elements. We are going to be using it to grab elements in the DOM.
Axios: Axios is an npm package, a promise-based HTTP Client for Node.js and the browser. We are going to be using it to get the website URL and return the content we want to scrap.
Express: Express is a fast, unopinionated, minimalist web framework for Node.js.
Nodemon: Nodemon is a simple monitor script for use during development of a Node.js App. We are going to use this package to create a local server to track the changes on the
index.jsfile.
Project Setup
To set the project for development, create a folder scrape-app and open it on VS Code like so 👇
Click on Ctrl + ` (backtick) to open up the VS Code terminal. 👇
Next, type the command below to generate a package.json file.
npm init -y
The -y flag which stands for Yes, will accept all the default options and generate a package.json file as shown below 👇.
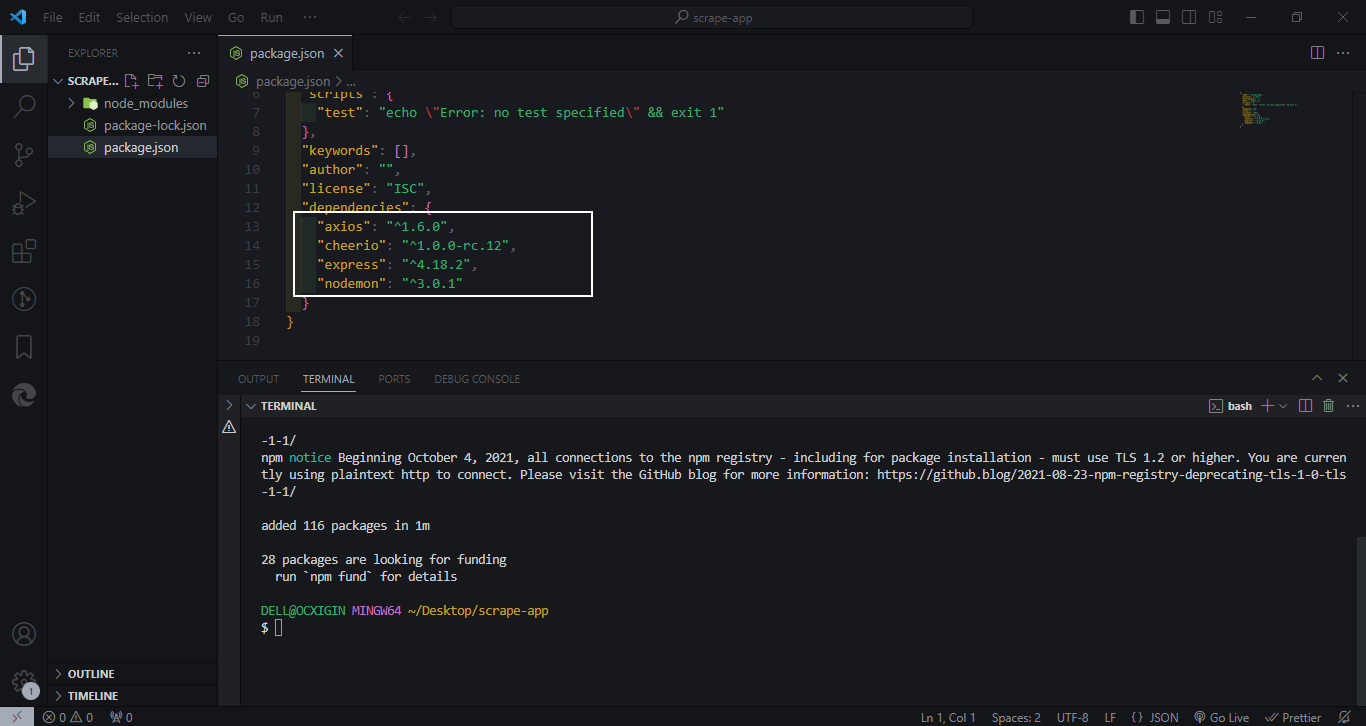
Next, install all four packages as indicated below 👇
npm install cheerio express axios nodemon
Next, npm will install all four packages (node_modules folder), package-lock.json and update the package.json file. 👇
Now, that we’ve installed the necessary dependencies, let’s create the index.js file as the entry point of our app.
Index.js file
To create the index.js file, type the command below 👇
touch index.js
You should see the new create index.js file as indicated below 👇
Express server setup
Open the index.js file and require the express module as indicated below. 👇
const express = require("express");
This is a commonJS syntax.
Next, create two variables called app and PORT, set the app to listen for the PORT server as specified below.
const PORT = 8000;
const app = express();
app.listen(PORT, () => console.log(`server running on PORT ${PORT}`));
The app will listen for changes in the file and log the result on the terminal.
Scraping data from a web page
Create a variable url and assign the absolute URL of the blog you want to scrape to it. 👇
const axios = require("axios");
const express = require("express");
const cheerio = require("cheerio");
const PORT = 8000;
const app = express();
👉 const url = "https://www.panmacmillan.com/blogs/general/must-read-books-of-all-time";
Specify the url as an argument on the axios() method like so 👇
axios(url)
Now, let's get the promise response (content) of the url parse in.
axios(url)
.then(response => {
const html = response.data;
const $ = cheerio.load(html);
const books = [];
})
The code example above is as follows;
html: we are getting the entire document of the page (The HTML document) and storing it into a constant variable ofhtml$:here, the returnhtmldocument which is parsed tocheerio.load(html), this will help load the HTML document to Cheerio and give us access to the Cheerio APIs for grabbing the HTML interface.book:this is an empty array where all the data entries will be stored as an object.
Next, let's inspect the DOM of the website we want to scrape.
Right-click on the screen and select inspect from the popup box or click F12 to open DevTools.
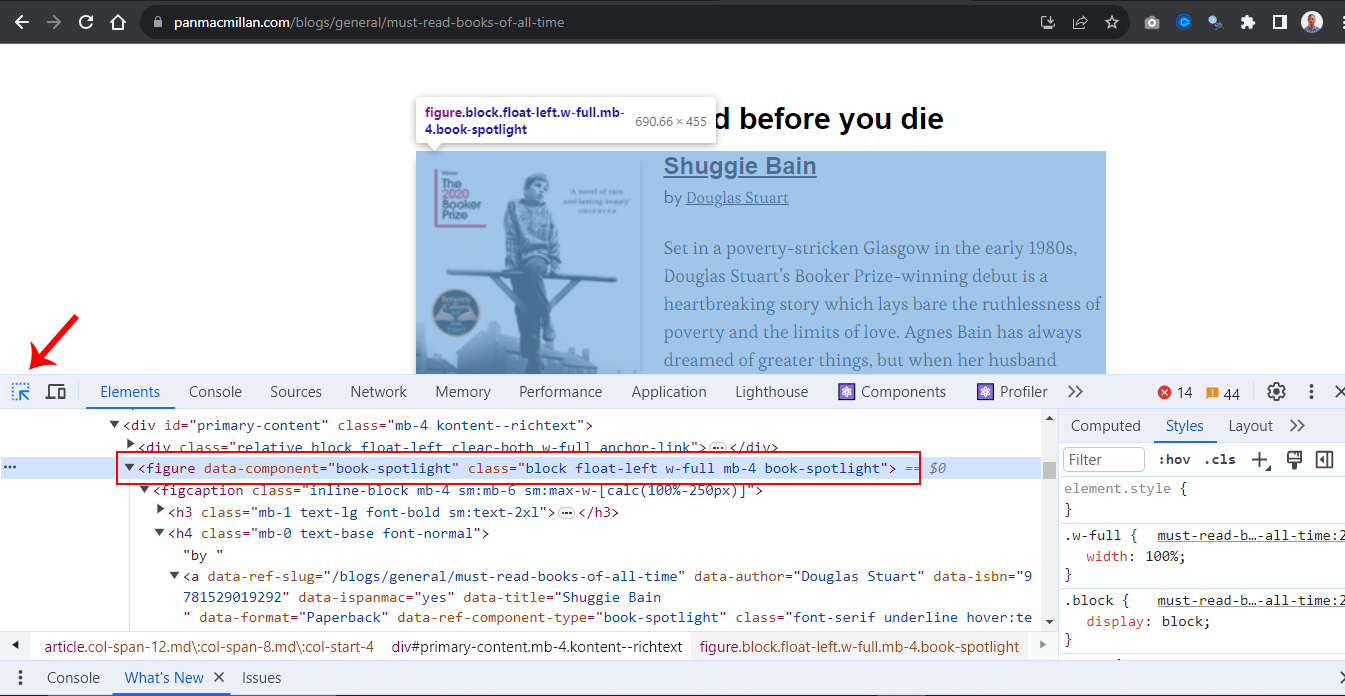
From the DevTools panel, click on the inspect icon and select the image. This will load the HTML document on the elements panel below the DevTools. Then select the figure tag with an data-component attribute.
The figure tag with a data-component attribute serves as the parent element for the main content we want to scrape, such as the id, title, author, about, imgURL.
Clicking on the figure tag with a data-component attribute will give you a highlight preview of the children elements as shown in the screenshot above. The select preview is the selected area on the webpage we want to scrape.

axios(url)
.then(response => {
const html = response.data;
const $ = cheerio.load(html);
const books = [];
👉 $("#primary-content figure[data-component='book-spotlight']", html)
})
From the code above, we targeted the #primary-content id which is the parent tag of the figure element and then we grabbed figure[data-component='book-spotlight'] attribute to be able to select the children's elements of the figure element where the data we want to return are.
axios(url)
.then(response => {
const html = response.data
const $ = cheerio.load(html)
const books = [];
$(
"#primary-content figure[data-component='book-spotlight']",
html
)
👉 .each(function () {
👉 const id = $(this).find("div a").attr("data-isbn");
👉 const title = $(this).find("figcaption h3 a").text();
👉 const author = $(this).find("figcaption h4 a span").text();
👉 const about = $(this).find("div.rte--default div p").text();
👉 const imgUrl = $(this).find("div a img").attr("src");
Next, the each() method is a callback function.
The
find()function is used to grab the element we want to returnThe
attr()function is used to grab the attribute of the return elementThe
text()function is used to return the text content within the element
The declared variable id, title, author, about, imgUrl stores the values of the return object.
const axios = require("axios");
const cheerio = require("cheerio");
const express = require("express");
const PORT = 8000;
const app = express();
const url =
"https://www.panmacmillan.com/blogs/general/must-read-books-of-all-time";
axios(url)
.then((response) => {
const html = response.data;
const $ = cheerio.load(html);
const books = [];
$("#primary-content figure[data-component='book-spotlight']", html).each(
function () {
const id = $(this).find("div a").attr("data-isbn");
const title = $(this).find("figcaption h3 a").text();
const author = $(this).find("figcaption h4 a span").text();
const about = $(this).find("div.rte--default div p").text();
const imgUrl = $(this).find("div a img").attr("src");
👉 books.push({
id,
title,
author,
about,
imgUrl,
});
}
);
👉 console.log(books);
})
app.listen(PORT, () => console.log(`server running on PORT ${PORT}`));
Next, we grab the book array and push all the return object values. This will return an array of objects based on the length (number of elements) of the parent element.
Then log the value to the terminal with console.log(books)
npm run start
Go to the Terminal and type the above command to start the dev server.
If for any reason the dev server does not start, check the package.json file and make sure the script is set as follows
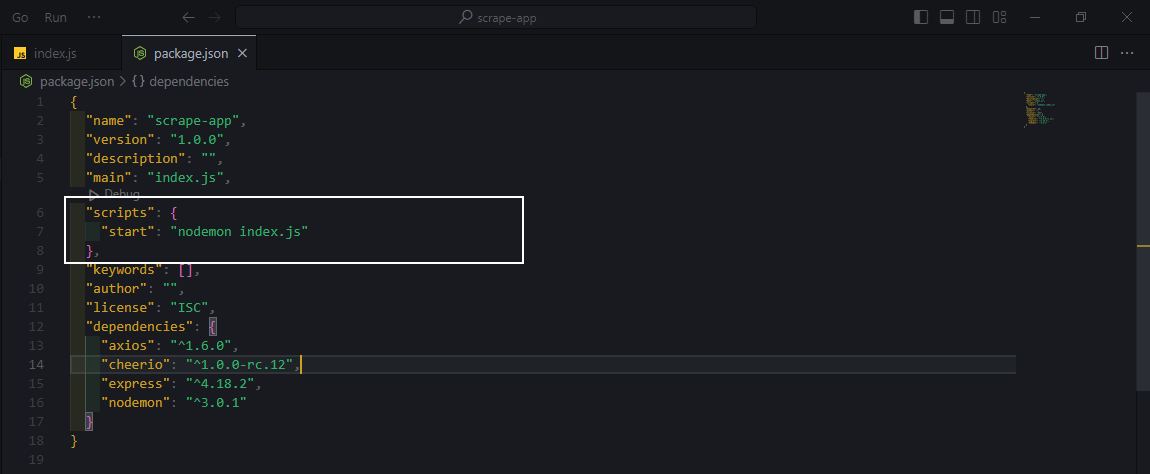
{
"name": "scrape-app",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
👉 "start": "nodemon index.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^1.6.0",
"cheerio": "^1.0.0-rc.12",
"express": "^4.18.2",
"nodemon": "^3.0.1"
}
}
Save the package.json file and type the command npm run start on the terminal to start the dev server. Once the server is started the value will be logged into the terminal.
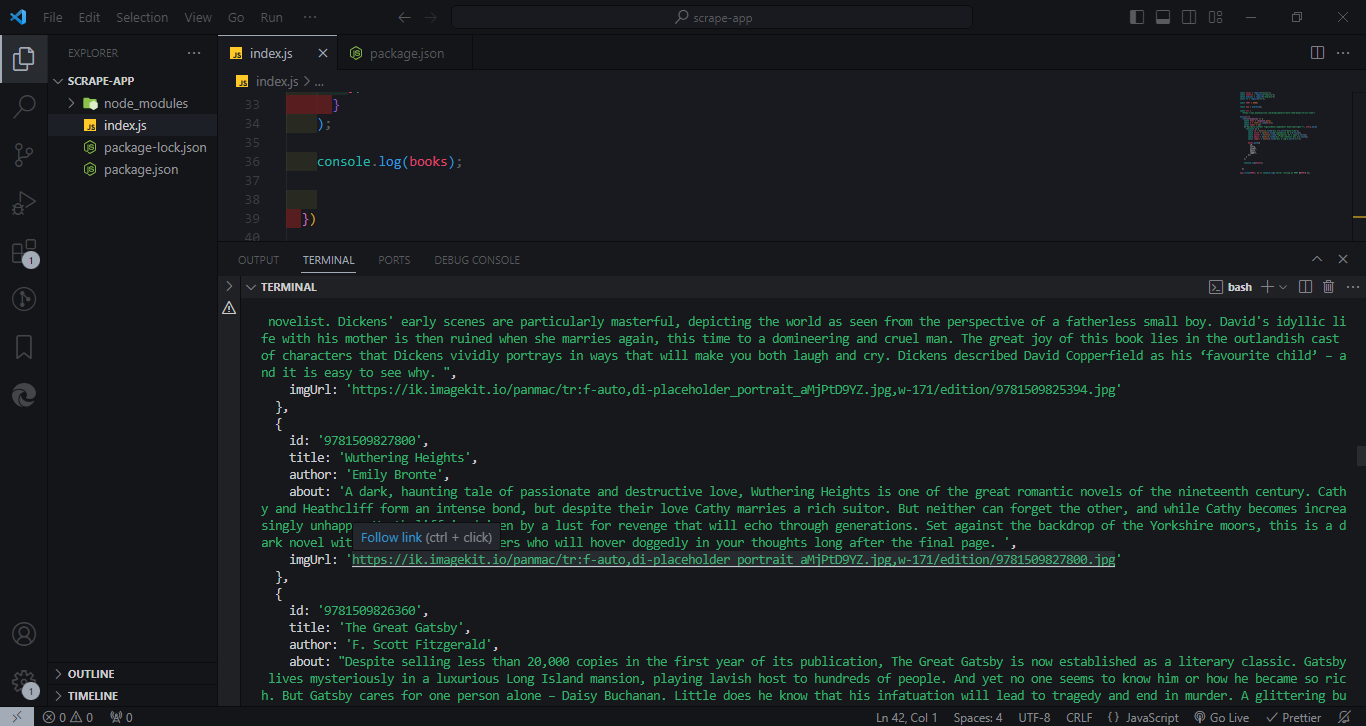
Now we have successfully scraped the data we want. The data we scraped is as follows
id: these are random numbers returned from a specificatag in the blogtitle: The title of each book in the blogauthor: the names of each author in the blogabout: description of each book in the blogimgUrl: The absolute URL of where the image is stored in the blog.
Furthermore, the JavaScript object can’t not be used from the console, we have to export it as a valid JSON file on the project folder.
Exporting scraped data
To export the data as a valid JSON file, require the fs module as follows
const fs = require("fs");
Next, specify how you want to export the file as follows
fs.writeFile("books.json", JSON.stringify(books), (err) => {
if (err) throw err;
console.log("book.js is now saved!");
})
The
fs.writeFlie(”books.json”)specifies the name of the fileThe
JSON.strigify(book)specifies the JavaScript object that needs to be exportedThe
errchecks and returns the error if any.
Save the index.js file and check the folder panel, the book.json should be saved. 🥳
Conclusion
Web Scraping is a very complicated yet simple technique. It can be useful in different cases and can reduce the amount of effort needed by a developer to create a valid JSON or API for their application.



